Learning Progress: 52.5%.
1 Introduction
数据和特征决定了机器学习的上限,而算法和模型只是逼近这个上限而已。 那么特征工程到底是什么呢? 顾名思义,其本质是一项工程运动,目的是最大限度地从原始数据中提取特征以供算法和模型使用。
特征工程可以总结如下:
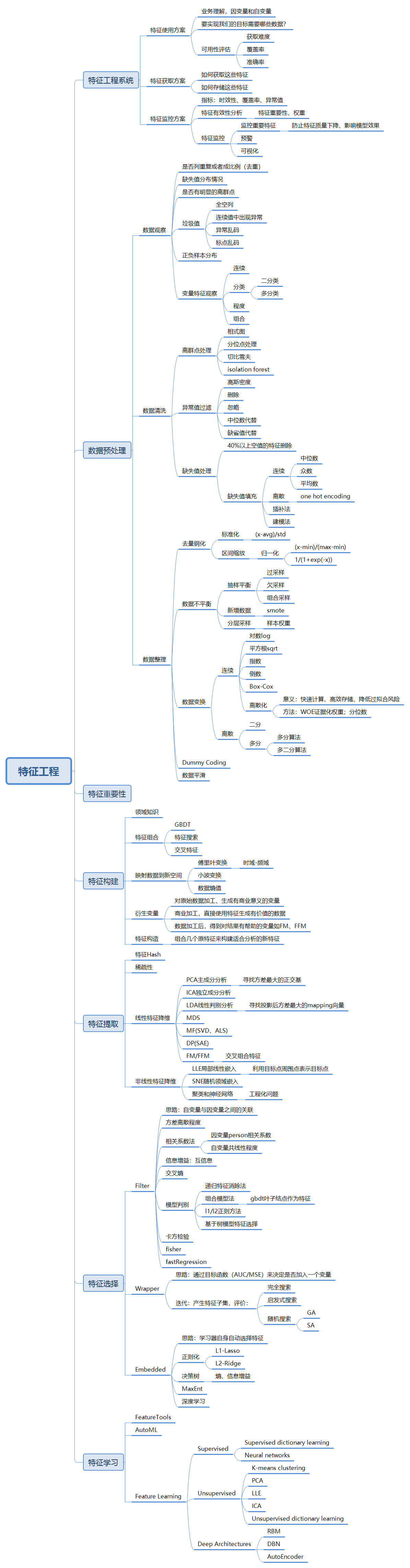
2 特征工程系统

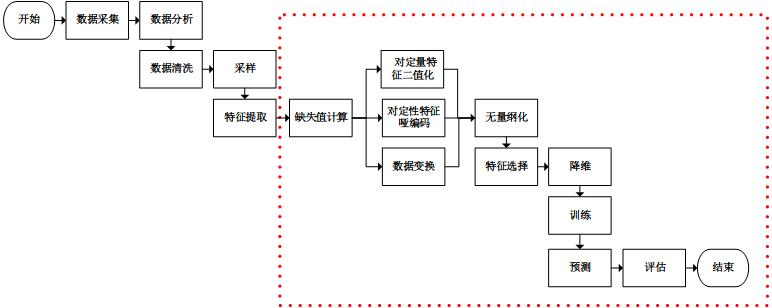
Figure 2.1 所示是一个经典的机器学习问题框架图。数据清洗和特征挖掘的工作是在灰色框中框出的部分,即“数据清洗=>特征,标注数据生成=>模型学习=>模型应用”中的前两个步骤。 灰色框中蓝色箭头对应的是离线处理部分。主要工作是:
从原始数据,如文本、图像或者应用数据中清洗出特征数据和标注数据。
对清洗出的特征和标注数据进行处理,例如样本采样,样本调权,异常点去除,特征归一化处理,特征变化,特征组合等过程。最终生成的数据主要是供模型训练使用。
以美团点击下单率预测为例,结合实例来介绍一个完整的特征工程系统。首先介绍下点击下单率预测任务,其业务目标是提高团购用户的用户体验,帮助用户更快更好地找到自己想买的单子。这个概念或者说目标看起来比较虚,我们需要将其转换成一个技术目标,便于度量和实现。最终确定的技术目标是点击下单率预估,去预测用户点击或者购买团购单的概率。我们将预测出来点击或者下单率高的单子排在前面,预测的越准确,用户在排序靠前的单子点击、下单的就越多,省去了用户反复翻页的开销,很快就能找到自己想要的单子。离线我们用常用的衡量排序结果的AUC指标,在线的我们通过ABTest来测试算法对下单率、用户转化率等指标的影响。
3 数据预处理
3.1 数据清洗
利用箱形图判断数据批的偏态和尾重:对于标准正态分布的样本,只有极少值为异常值。异常值越多说明尾部越重,自由度越小(即自由变动的量的个数)。而偏态表示偏离程度,异常值集中在较小值一侧,则分布呈左偏态;异常值集中在较大值一侧,则分布呈右偏态。
iForest(Isolation Forest)孤立森林是一个基于Ensemble的快速异常检测方法,具有线性时间复杂度和高精准度,是符合大数据处理要求的state-of-the-art算法。其可以用于网络安全中的共计检测,金融交易欺诈检测,疾病检测和噪声数据过滤等。iForest适用于连续数据的异常检测,将异常定义为“容易被孤立的离群点”——可以理解为分布稀疏且离密度高的群体较远的点。用统计学来解释,在数据空间里面,分布稀疏的区域表示数据发生在此区域的概率很低,因此可以认为落在这些区域里的数据是异常的。如 Figure 3.2 所示,黑色的点为异常点,白色点为正常点(在一个簇中)。iForest检测到的异常边界为红色,它可以正确地检测到所有黑色异常点。
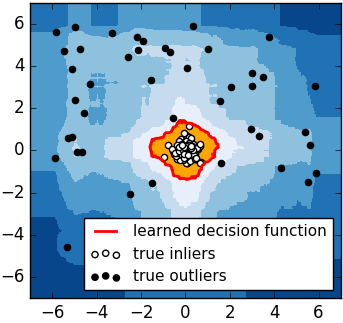
iForest属于Non-parametric和unsupervised的方法,即不用定义数学模型也不需要有标记的训练。对于如何查找哪些点是否容易被孤立(isolated),iForest使用了一套非常高效的策略。假设我们用一个随机超平面来切割(split)数据空间(data space), 切一次可以生成两个子空间(想象拿刀切蛋糕一分为二)。之后我们再继续用一个随机超平面来切割每个子空间,循环下去,直到每子空间里面只有一个数据点为止。直观上来讲,我们可以发现那些密度很高的簇是可以被切很多次才会停止切割,但是那些密度很低的点很容易很早的就停到一个子空间了。上图里面黑色的点就很容易被切几次就停到一个子空间,而白色点聚集的地方可以切很多次才停止。
iForest优缺点:
具有线性时间复杂度,可以用在含有海量数据的数据集上面。通常树的数量越多,算法越稳定。由于每棵树都是互相独立生成的,因此可以部署在大规模分布式系统上来加速运算。
iForest不适用于特别高维的数据。由于每次切数据空间都是随机选取一个维度,建完树后仍然有大量的维度信息没有被使用,导致算法可靠性降低。高维空间还可能存在大量噪音维度和无关维度,影响树的构建。
iForest仅对Global Anomaly敏感,即全局稀疏点敏感,不擅长处理局部的相对稀疏点。目前已有改进方法发表:Improving iForest with Relative Mass。
3.2 数据整理
标准化的前提是特征值服从正态分布,标准化后,其转换成标准正态分布。Z-score 标准化指的是,通过缩放让数据的均值为0(移除均值),标准差为固定值(比如1)。在许多模型里,如SVM的RBF、线性模型的 L1 & L2 正则项对于所有的feature都有这样的假设。
标准化和归一化的区别: 简单来说,标准化是依照特征矩阵的列处理数据,其通过求z-score的方法,将样本的特征值转换到同一量纲下。归一化是依照特征矩阵的行处理数据,其目的在于样本向量在点乘运算或其他核函数计算相似性时,拥有统一的标准,也就是说都转化为“单位向量”。
4 特征构建
4.1 衍生变量和特征构造
有时候原生变量不能完全满足预测的要求,那么可以根据一个或者多个原生变量衍生出其它可用或不可用的变量,这一过程称为“变量衍生”。变量衍生是特征工程一个比较重要的组成部分,它需要花费比较多的精力和时间尽量去认识原生变量和具体的预测命题,然后根据原生变量的特点构造出一些衍生变量。比如拿到一个“手机号码”,根据这个变量我们可以衍生出“运营商”,“归属地省份”,“归属地城市”,根据“归属地城市”又可以衍生出“是否一级城市”,“是否偏远城市”等等,总之,如何从原生数据中挖出有预测能力的变量是一项需要脑洞和脑力的工程。
对原始数据加工、生成有商业意义的变量:如通过每次登录的相关信息登陆表衍生出”最近30天的登录次数“这个变量。
商业加工,直接使用特征生成有价值的数据:数据加工后,得到对结果有帮助的变量如FM,FFM。
5 特征提取
特征提取是自动地对原始观测降维,使其特征集合小到可以进行建模的过程。特征提取的意义就是在于把复杂的数据,如文本和图像,转化为数字特征,以便在机器学习中使用。
特征提取和特征选择都属于降维。不同之处在于特征提取是在原有特征基础之上去创造凝练出一些新的特征,而特征选择只是在原有特征上进行筛选。
5.1 稀疏表示
将数据集 \(\mathbf{D}\) 表示为矩阵,每一行对应一个样本,每列对应于一种特征。特征选择所考虑的问题是特征具有稀疏性:即矩阵中的许多列与当前学习无关。通过特征选择去掉这些列,则学习器训练过程仅需在较小的矩阵上进行,学习难度会有所降低,计算和存储开销减小,模型的可解释性也会提高。此外,模型的输入因素减少了,模型建立的输入输出关系会更清晰。
现在看另一种“稀疏性”:\(\mathbf{D}\) 对应的矩阵存在很多零元素,杂乱分布,而非整行整列的形式。比如文档分类中,每行是一个文档样本,每列代表一个字,字在文档中出现的频率作为特征取值。《康熙字典》有47035个汉字,则矩阵有4万多列。而文档中很多字不会出现,导致每一行有大量的零元素。
当样本具有稀疏表示时,它有以下优势:
数据具有稀疏性能使得大多数问题变得线性可分;
稀疏样本有高效的存储方法,不会造成存储的巨大负担。
这便是稀疏表示与字典学习的基本出发点。
5.1.1 字典学习
稀疏矩阵即矩阵的每一行/列中都包含了大量的零元素,且这些零元素没有出现在同一行/列,对于一个给定的稠密矩阵,若我们能通过某种方法找到其合适的稀疏表示,则可以使得学习任务更加简单高效,我们称之为稀疏编码(sparse coding)或字典学习(dictionary learning)。
给定一个数据集,字典学习/稀疏编码指的便是通过一个字典将原数据转化为稀疏表示,因此最终的目标就是求得字典矩阵 \(\mathbf{\beta}\) 及稀疏表示 \(\alpha\),使用变量交替优化的策略能较好地求得解。
5.1.2 压缩感知
压缩感知是指直接感知压缩后的信息,其目的是从尽量少的数据中提取尽量多的信息。
在实际问题中,为了方便传输和存储,我们一般将数字信息进行压缩,这样就有可能损失部分信息,如何根据已有的信息来重构出全部信号,这便是压缩感知的来源。与特征选择、稀疏表示不同的是:它关注的是如何利用信号本身具有的稀疏性,通过欠采样信息来恢复全部信息。压缩感知的前提是已知的信息具有稀疏表示。
5.2 特征 hash
特征哈希法的目标是把原始的高维特征向量压缩成较低维特征向量,且尽量不损失元素特征值的表达能力。